Running Local LLMs on an M4 Mac mini 16GB — Practical Options and Limits

Introduction
A local LLM was tested on a 16GB Mac mini. It is not fast, but it is practical enough, and when power consumption is factored in as well (around 30W under load), it is a decent option.
This article is a record of model selection, runtime selection, setup steps, and the pitfalls encountered while running local LLMs on an M4 Mac mini base model (16GB unified memory). The main topic is the issue discussed in the second half: what was really happening behind the “slow responses / no actual reply body returned” behavior when running the Qwen3.5 family on Ollama.
1. The Constraint of 16GB
With 16GB of unified memory, the largest models that run comfortably are in the 7–9B class at Q4 quantization. Once a model exceeds 14B at Q4, it starts swapping to virtual memory, throughput drops below 5 tok/s, and it is no longer practical.
And the real limit is not just model size. KV cache and context length also consume memory. Even if the model itself fits, things can still fall apart once long contexts are involved or other applications are running in the background. With 16GB, the right question is not “Does the model fit?” but rather “Can the model + KV cache + OS + working apps all fit at the same time?”
2. Architectural Differences Between Unified Memory and NVIDIA GPUs
For comparison, here is how it stacks up against an NVIDIA GeForce RTX 3060 12GB on hand.
| Aspect | RTX 3060 12GB | M4 Mac mini 16GB |
|---|---|---|
| Memory bandwidth | 360 GB/s (GDDR6) | 120 GB/s (LPDDR5X) |
| 7-8B Q4 speed | approx. 38-45 tok/s | approx. 20-35 tok/s |
| Memory capacity | Dedicated 12GB (hard capacity wall) | Unified 16GB (more gradual degradation) |
| prefill | Strong (CUDA) | Weak |
| Power consumption | 170W class | approx. 30W |
| Ecosystem | CUDA (mature) | MLX / Metal |
LLM token generation is largely memory-bandwidth-bound, so NVIDIA GPUs—with roughly 3× the bandwidth—deliver higher raw generation speed. On the other hand, Macs benefit from flexible unified memory, low power consumption, quiet operation, and suitability for 24/7 use. This is not a matter of one being strictly better; they simply have different characteristics.
3. Model Selection
The daily driver is Qwen3.5-9B (Q4_K_M, about 6.6GB, Ollama tag qwen3.5:9b). It fits comfortably within 16GB and supports 256K context, vision, tools, and thinking.
One correction is worth making: there is no model called “Qwen3.6-9B.” The 9B model belongs to the Qwen3.5 family. The Qwen3.6 family only includes dense 27B and 35B-A3B (MoE). In MoE, A3B (active 3B) refers to speed and compute per token—only 3B parameters are active for each token—but the full 35B still has to be loaded into memory. Misunderstanding this leads to the mistaken assumption that “it is effectively 3B, so it should run in 16GB.”
4. Runtime Selection
The local inference stack is best understood as three layers:
- GGML: A C tensor computation library (matrix ops, memory management, GPU kernels). The foundation.
- llama.cpp: Implements inference itself on top of GGML (model loading, forward pass, sampling, GGUF,
llama-server). It is the core of almost every local inference tool. - Ollama: An operational wrapper built on top of llama.cpp (
ollama pull, Modelfile, automatic memory management, OpenAI-compatible API).
Ollama briefly moved away from llama.cpp and experimented with its own engine, but in May 2026 it returned to upstream llama.cpp (llama-server). The current split is essentially “GGUF via llama.cpp, safetensors on Apple Silicon via MLX.”
For 16GB systems, Ollama-GGUF is the practical choice. Ollama’s MLX backend recommends 32GB+ unified memory, and on 16GB it falls back to llama.cpp. If maximum MLX performance is the goal, mlx-lm should be used directly instead of Ollama. But for a 16GB always-on server, Ollama-GGUF is the straightforward choice.
5. Setup
In principle, this is all that is needed.
ollama pull qwen3.5:9b
OLLAMA_HOST=0.0.0.0 ollama serve # Expose it so other devices on the LAN can connect
There is one pitfall here. The Homebrew formula build of ollama (0.30.x series) does not bundle the llama-server binary and therefore cannot start (GitHub issue #16535). It stops with llama-server binary not found. The fix is to use the official build (the .dmg from ollama.com, or brew install --cask ollama-app). The CLI will then use the bundled llama-server that ships with the app.
Do not get overly ambitious with context length at the start. It is safer to begin with a fixed 8K–16K. For an always-on server, it is best to pin it in a Modelfile.
cat > Modelfile <<'EOF'
FROM qwen3.5:9b
PARAMETER num_ctx 8192
PARAMETER temperature 0.3
EOF
ollama create qwen-dev -f Modelfile
To verify that the model is actually loaded into unified memory, check ollama ps. If it falls back to swap, perceived performance collapses, so this is something that should always be checked.
6. Measurements and Pitfalls (Main Topic)
This is the core of the article. Raw generation speed on a 9B model / M4 base is about 18 tok/s. That is the baseline performance of this setup.
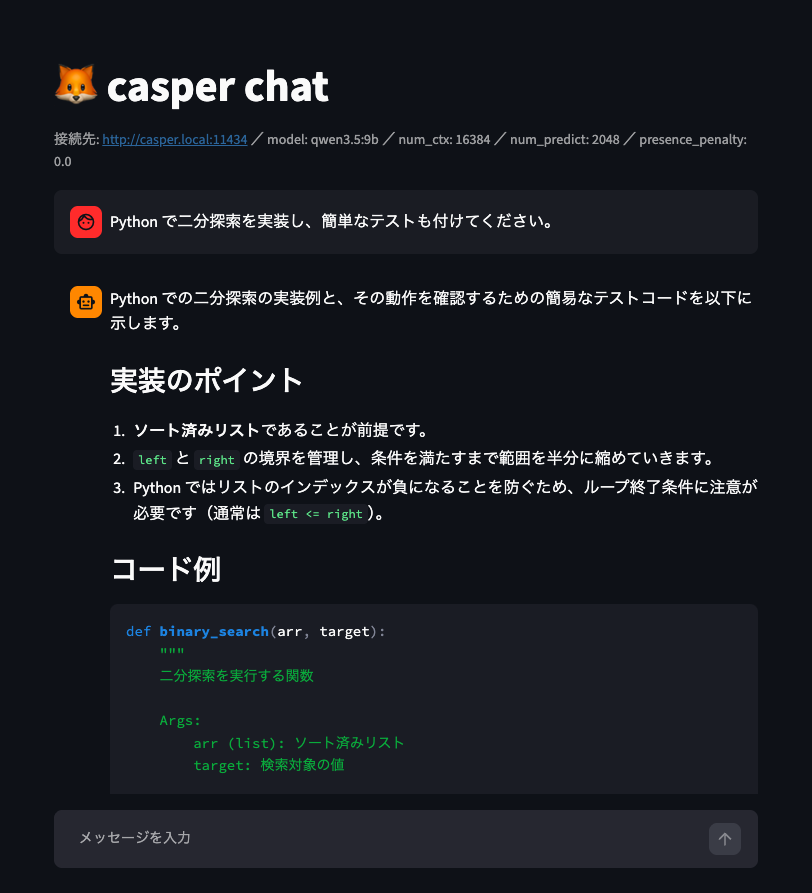
However, at first, even an input as simple as “こんにちは” took 30–60 seconds, and sometimes an empty response came back. After working through the possible causes one by one, the root cause turned out to fall into three parts.
Root Cause 1: thinking (Most Important)
Qwen3.5 is a reasoning model, and if think is not specified explicitly, thinking is enabled by default. In this case, output is sent to the message.thinking field, while message.content remains empty. Then, if the thinking process consumes the entire num_predict budget (the maximum number of generated tokens), generation is cut off with done_reason: length before it ever reaches the answer, and content stays empty all the way to the end.
An actual curl test showed exactly that: content was empty, while thinking was filled with 256 tokens. That was the true nature of the “empty reply.”
The fix is to set think to false. However, there are two details to watch out for (Ollama issue #14793):
thinkmust be passed as a top-level parameter, not insideoptions.- It must be passed through the chat API (there is a bug where the generate API ignores
think: false).
curl http://your-host:11434/api/chat -d '{
"model": "qwen3.5:9b",
"messages": [{"role": "user", "content": "あなたの知識カットオフの年月日を教えて。1文で簡潔に。"}],
"stream": false,
"think": false,
"options": {"presence_penalty": 0.0, "num_predict": 256}
}'
With think: false, the same question produced a proper answer in content, at 16 tokens and in 6 seconds.
That said, accuracy drops significantly compared with leaving thinking enabled. This is simply a machine-spec limitation, so some compromise is unavoidable.
Root Cause 2: presence_penalty = 1.5
Ollama’s default presence_penalty for qwen3.5 is a high 1.5. This parameter strongly penalizes previously used tokens to encourage novelty, and at 1.5 it tends to push the model toward “keep introducing new things instead of wrapping up,” which becomes a secondary cause of overlong responses. Lowering it to 0 makes responses end naturally at an appropriate length.
Notes on num_predict
If num_predict is set to 4096, then when the behavior above runs out of control, the model generates all 4096 tokens, which at 18 tok/s takes 3 minutes and 48 seconds. Waiting that long for every failed attempt is draining, so it is better to lower it to 512–1024 and limit the damage. Once thinking is disabled, normal responses finish well before that anyway, so 512 is sufficient.
Initial Misdiagnosis and Correction
At first, empty responses during multi-turn conversations were suspected to be caused by “a context cache bug in the Qwen3.5 hybrid architecture.” But after inspecting the response JSON, it became clear that the real reason was much simpler: thinking was consuming the entire token budget. The behavior of “works for single-turn, but returns empty on multi-turn” is also fully explained by whether the thinking process fits within the budget or overflows it. After local verification, that original conclusion had to be corrected.
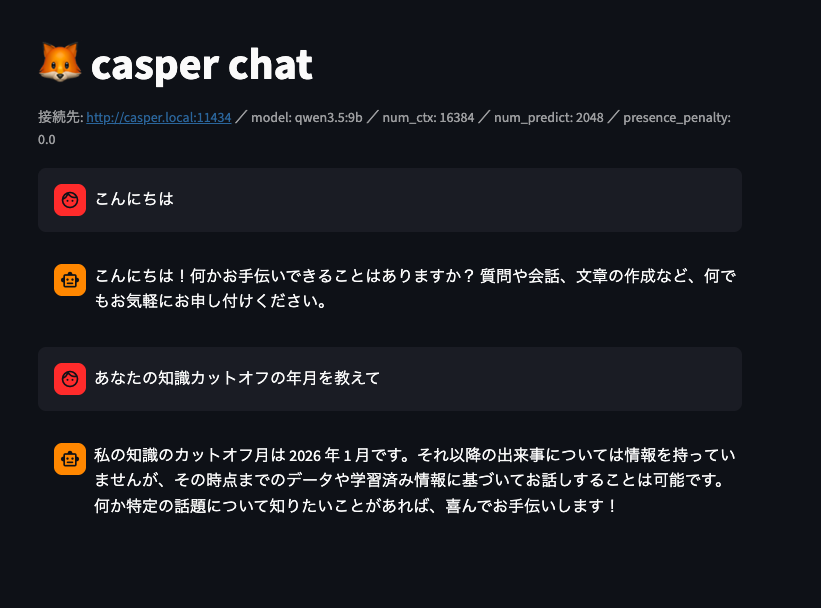
Self-Reported Cutoff Dates Are Not Reliable
As a side note: if asked, “When is your knowledge cutoff?”, the model may reply with something like “2026,” but this is not trustworthy. The model does not carry the exact final date of its training data as a retrievable fact; it is simply generating a plausible-looking value. It is not something that can be used as a benchmark indicator.
This was also discussed on Reddit
Confirmed Settings
think: false
presence_penalty: 0.0
num_predict: 512
7. Chat App for Connecting
A simple chat app for connecting to Ollama on the Mac mini over LAN was written as a single-file script using PEP 723 + uv. With the #!/usr/bin/env -S uv run --script shebang and inline script metadata, everything fits in one file, including dependencies (streamlit / ollama / watchdog).
(By the way, casper is the name of the Mac mini used for testing.)
#!/usr/bin/env -S uv run --script
# /// script
# requires-python = ">=3.11"
# dependencies = [
# "streamlit>=1.43",
# "ollama",
# "watchdog",
# ]
# ///
"""
casper_chat_vision.py — A portable single-file chat app with image input support that talks to Ollama on casper
This is casper_chat.py with image attachment support added. It can send images to
vision-capable models such as Qwen3.5-9B. Attach an image from the clip (📎) in the chat input area and send it.
Run:
chmod +x casper_chat_vision.py
./casper_chat_vision.py
→ uv automatically installs dependencies into an isolated environment and launches it in the browser
If the shebang cannot be used in your environment:
uv run --script casper_chat_vision.py
Requirements:
Ollama must be running on casper with LAN exposure enabled
OLLAMA_HOST=0.0.0.0 ollama serve
A vision-capable model must already be pulled (qwen3.5:9b is supported)
ollama pull qwen3.5:9b
Notes:
- Image attachments are limited to the extensions listed in file_type. Sending them to a non-vision model will cause an error.
- Images are added to the conversation history and resent on every turn (re-prefill). Since the M4 is weak at prefill,
large images, multiple images, or long conversations will make it slow. If it gets heavy, use “Clear conversation” or resize the images.
"""
# pyright: reportMissingImports=false
import sys
def run_app() -> None:
"""Main application body that runs under the Streamlit runtime."""
import streamlit as st
from ollama import Client
# ---- Default settings (can be overridden in the sidebar) ----
DEFAULT_HOST = "http://casper.local:11434"
DEFAULT_MODEL = "qwen3.5:9b"
IMAGE_TYPES = ["png", "jpg", "jpeg", "webp", "gif", "bmp"]
st.set_page_config(page_title="casper chat (vision)", page_icon="🦊")
st.title("🦊 casper chat (vision)")
with st.sidebar:
st.header("Settings")
host = st.text_input("Ollama host", DEFAULT_HOST)
model = st.text_input("Model", DEFAULT_MODEL)
st.caption("Use a vision-capable model (for example: qwen3.5:9b) if you want to send images.")
num_ctx = st.selectbox(
"context window (num_ctx)",
[4096, 8192, 16384, 32768],
index=2, # default 16384
help="Total upper limit for conversation history + generation. Changing this causes Ollama to reload the model."
"Images consume many tokens, so if you are using images, a larger value is safer.",
)
unlimited = st.checkbox(
"No output limit (until EOS, num_predict=-1)", value=False
)
num_predict_slider = st.slider(
"max tokens (num_predict)", 256, 8192, 2048, 256
)
num_predict = -1 if unlimited else num_predict_slider
temperature = st.slider("temperature", 0.0, 1.5, 0.3, 0.1)
# presence_penalty: Ollama's default for qwen3.5 is 1.5, and this is the main cause of rambling overlong responses.
# Setting it to 0 makes responses end naturally at an appropriate length. If repetition becomes noticeable, raise it to around 0.3.
presence_penalty = st.slider(
"presence_penalty", 0.0, 1.5, 0.0, 0.1,
help="The model default of 1.5 causes runaway verbosity. Set to 0 for appropriate length. If it repeats, try around 0.3.",
)
# thinking: when ON, reasoning goes to the thinking field and content is more likely to stay empty (#14793).
# Default OFF = answer appears directly in content and is faster.
think_enabled = st.checkbox(
"Enable thinking (reasoning for inference models)", value=False,
help="OFF is recommended. When ON, it spends budget on thinking and is more likely to become slow / return an empty reply.",
)
if st.button("Clear conversation", use_container_width=True):
st.session_state.messages = []
st.rerun()
np_label = "Unlimited (until EOS)" if num_predict == -1 else str(num_predict)
st.caption(
f"Connected to: {host} / model: {model} / num_ctx: {num_ctx} / "
f"num_predict: {np_label} / presence_penalty: {presence_penalty}"
)
client = Client(host=host)
# ---- Conversation history (multi-turn persistence) ----
# Each user message uses the format {"role","content","images"?}.
# images is a list of bytes (ollama-python automatically base64-encodes them).
if "messages" not in st.session_state:
st.session_state.messages = []
def render_message(m: dict) -> None:
"""Render one history entry. Show content and attached images."""
with st.chat_message(m["role"]):
if m.get("content"):
st.markdown(m["content"])
for img in m.get("images", []):
st.image(img, width=240)
for m in st.session_state.messages:
render_message(m)
# ---- Input (text + image attachments) → streaming response ----
chat = st.chat_input(
"Enter a message (you can also attach images from 📎)",
accept_file="multiple",
file_type=IMAGE_TYPES,
)
if chat:
text = (chat.text or "").strip()
images = [f.getvalue() for f in (chat.files or [])]
if not text and not images:
st.stop() # Ignore empty submissions
user_msg = {"role": "user", "content": text}
if images:
user_msg["images"] = images
st.session_state.messages.append(user_msg)
render_message(user_msg)
with st.chat_message("assistant"):
thinking_box = None
if think_enabled:
thinking_box = st.expander("🧠 thinking", expanded=False).empty()
content_box = st.empty()
thinking_text = ""
content_text = ""
try:
# Pass think at the top level, not inside options (Ollama chat API behavior / #14793).
for chunk in client.chat(
model=model,
messages=st.session_state.messages,
stream=True,
think=think_enabled,
options={
"num_ctx": num_ctx,
"num_predict": num_predict,
"temperature": temperature,
"presence_penalty": presence_penalty,
},
):
msg = chunk["message"]
t = msg.get("thinking") or ""
c = msg.get("content") or ""
if t and thinking_box is not None:
thinking_text += t
thinking_box.markdown(thinking_text)
if c:
content_text += c
content_box.markdown(content_text)
except Exception as e:
content_text = (
f"We look forward to discussing your development needs.